
文章目录
一、概述
Squeeze-and-Excitation Networks(简称 SENet)是 Momenta 胡杰团队(WMW)提出的新的网络结构,利用SENet,一举取得最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
作者在文中将SENet block插入到现有的多种分类网络中,都取得了不错的效果。作者的动机是希望显式地建模特征通道之间的相互依赖关系。另外,作者并未引入新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
通俗的来说SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SE block嵌在原有的一些分类网络中不可避免地增加了一些参数和计算量,但是在效果面前还是可以接受的 。Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。
二、结构和原理
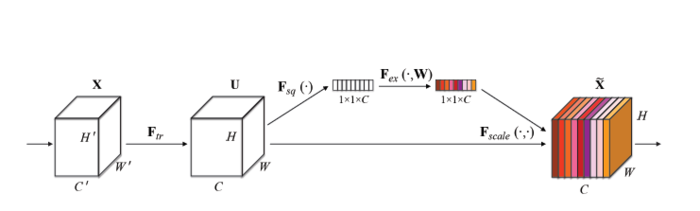
图1.SE Block
图1是SENet的Block单元。
图中的Ftr是传统的卷积结构,X和U是Ftr的输入(C’ x ‘H’ x W’)和输出(C x H x W),这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。
- 首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
- 其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
- 最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
下面来看下SENet的一些细节:
? Squeeze: Global Information Embedding
挤压:全局信息嵌入
(1)Squeeze :特征U通过 squeeze 压缩操作,将跨空间维度H × W的特征映射进行聚合,生成一个通道描述符,HxWxC → 1x1xC ;
将 全局空间信息 压缩到上述 通道描述符 中,使来这些 通道描述符 可以被 其输入的层 利用,这里采用的是 global average pooling ;->GAP(和CAM一样)

Excitation: Adaptive Recalibration
? Excitation: Adaptive Recalibration
激励:自适应调整
(2)Excitation :每个通道通过一个 基于通道依赖 的自选门机制 来学习特定样本的激活,使其学会使用全局信息,有选择地强调信息特征,并抑制不太有用的特征,这里采用的是 sigmoid ,并在中间嵌入了 ReLU 函数用于限制模型的复杂性和帮助训练 ;
通过 两个全连接层(FC) 构成的瓶颈来参数化门控机制,即 W1 用于降低维度,W2 用于维度递增 ;
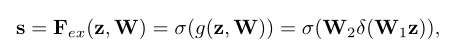
(3)Reweight :将 Excitation 输出的权重通过乘法逐通道加权到输入特征上;
总的来说 SE Block 就是在 Layer 的输入和输出之间添加结构: global average pooling – FC – ReLU – FC– sigmoid ;
SE block 的灵活性意味着它可以直接应用于标准卷积以外的转换,通过将 SE block 集成到任何复杂模型当中来开发SENet;
代码复现
# Here is the code :
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary
class SE_Block(nn.Module): # Squeeze-and-Excitation block
def __init__(self, in_planes):
super(SE_Block, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.conv1 = nn.Conv2d(in_planes, in_planes // 16, kernel_size=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_planes // 16, in_planes, kernel_size=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.avgpool(x)
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
out = self.sigmoid(x)
return out
class BasicBlock(nn.Module): # 左侧的 residual block 结构(18-layer、34-layer)
expansion = 1
def __init__(self, in_planes, planes, stride=1): # 两层卷积 Conv2d + Shutcuts
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.SE = SE_Block(planes) # Squeeze-and-Excitation block
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes: # Shutcuts用于构建 Conv Block 和 Identity Block
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module): # 右侧的 residual block 结构(50-layer、101-layer、152-layer)
expansion = 4
def __init__(self, in_planes, planes, stride=1): # 三层卷积 Conv2d + Shutcuts
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.SE = SE_Block(self.expansion*planes) # Squeeze-and-Excitation block
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes: # Shutcuts用于构建 Conv Block 和 Identity Block
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
SE_out = self.SE(out)
out = out * SE_out
out += self.shortcut(x)
out = F.relu(out)
return out
class SE_ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=1000):
super(SE_ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1, bias=False) # conv1
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # conv2_x
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # conv3_x
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # conv4_x
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # conv5_x
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
out = self.linear(x)
return out
def SE_ResNet18():
return SE_ResNet(BasicBlock, [2, 2, 2, 2])
def SE_ResNet34():
return SE_ResNet(BasicBlock, [3, 4, 6, 3])
def SE_ResNet50():
return SE_ResNet(Bottleneck, [3, 4, 6, 3])
def SE_ResNet101():
return SE_ResNet(Bottleneck, [3, 4, 23, 3])
def SE_ResNet152():
return SE_ResNet(Bottleneck, [3, 8, 36, 3])
def test():
net = SE_ResNet50()
y = net(torch.randn(1, 3, 224, 224))
print(y.size())
summary(net, (1, 3, 224, 224))
if __name__ == '__main__':
test()
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏