
一、概述
SKNet是SENet的孪生兄弟,SENet是结合通道注意力,SKNet则是结合了卷积注意力。
Selective Kernel Networks(SKNet)发表在CVPR 2019,SKNet是SENet的加强版,结合了SE opetator、Merge-and-Run Mappings以及attention on inception block的产物。名为SK模块, 可以自适应调节自身的感受野。
之前的SENet是对特征图的通道注意力机制的研究,而SKNet则是针对卷积核的注意力机制研究。
SK模块核心思想就是:用multiple scale feature汇总的information来channel-wise地指导如何分配侧重使用哪个kernel的表征
不同大小的感受视野(卷积核)对于不同尺度(远近、大小)的目标会有不同的效果。尽管比如Inception这样的增加了多个卷积核来适应不同尺度图像,但是一旦训练完成后,参数就固定了,这样多尺度信息就会被全部使用了(每个卷积核的权重相同)。
因此,SKNet提出了一种机制,即卷积核的重要性。SKNet对不同图像使用的卷积核权重不同,即一种针对不同尺度的图像动态生成卷积核。
据作者说,该模块在超分辨率任务上有很大提升,并且论文中的实验也证实了在分类任务上有很好的表现。
分组卷积
通卷积:
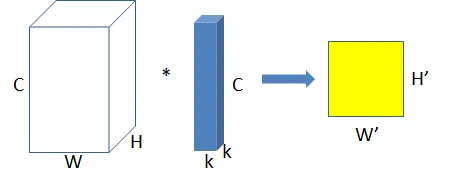
上图为普通卷积示意图,为方便理解,图中只有一个卷积核,此时输入输出数据为:
输入feature map尺寸: W×H×C ,分别对应feature map的宽,高,通道数;
单个卷积核尺寸: k×k×C ,分别对应单个卷积核的宽,高,通道数;
输出feature map尺寸 :W’×H’ ,输出通道数等于卷积核数量,输出的宽和高与卷积步长有关,这里不关心这两个值。参数量
运算量,这里只考虑浮点乘数量,不考虑浮点加。
group convolution (分组卷积):
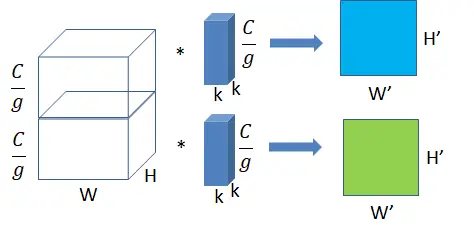
将图一卷积的输入feature map分成组,每个卷积核也相应地分成组,在对应的组内做卷积,如上图2所示,图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成个feature map。输入每组feature map尺寸: ,共有
组;
单个卷积核每组的尺寸:,一个卷积核被分成了
组;
输出feature map尺寸:,共生成
个feature map。
现在我们再来计算一下分组卷积时的参数量和运算量:
参数量
运算量
我们居然用了同等的参数量运算量生成了个feature map!!!
所以group conv常用在轻量型高效网络中,因为它用少量的参数量和运算量就能生成大量的feature map,大量的feature map意味着能够编码更多的信息!
从分组卷积的角度来看,分组数就像一个控制旋钮,最小值是1,此时
的卷积就是普通卷积;最大值是输入feature map的通道数
,此时
的卷积就是depthwise sepereable convolution,即深度分离卷积,又叫逐通道卷积。
二、结构和原理
(1)多分支的卷积网络


代码实现
import torch.nn as nn
import torch
from functools import reduce
class SKConv(nn.Module):
def __init__(self,in_channels,out_channels,stride=1,M=2,r=16,L=32):
'''
:param in_channels: 输入通道维度
:param out_channels: 输出通道维度 原论文中 输入输出通道维度相同
:param stride: 步长,默认为1
:param M: 分支数
:param r: 特征Z的长度,计算其维度d 时所需的比率(论文中 特征S->Z 是降维,故需要规定 降维的下界)
:param L: 论文中规定特征Z的下界,默认为32
'''
super(SKConv,self).__init__()
d=max(in_channels//r,L) # 计算向量Z 的长度d
self.M=M
self.out_channels=out_channels
self.conv=nn.ModuleList() # 根据分支数量 添加 不同核的卷积操作
for i in range(M):
# 为提高效率,原论文中 扩张卷积5x5为 (3X3,dilation=2)来代替。 且论文中建议组卷积G=32
self.conv.append(nn.Sequential(nn.Conv2d(in_channels,out_channels,3,stride,padding=1+i,dilation=1+i,groups=32,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
self.global_pool=nn.AdaptiveAvgPool2d(1) # 自适应pool到指定维度 这里指定为1,实现 GAP
self.fc1=nn.Sequential(nn.Conv2d(out_channels,d,1,bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=True)) # 降维
self.fc2=nn.Conv2d(d,out_channels*M,1,1,bias=False) # 升维
self.softmax=nn.Softmax(dim=1) # 指定dim=1 使得两个全连接层对应位置进行softmax,保证 对应位置a+b+..=1
def forward(self, input):
batch_size=input.size(0)
output=[]
#the part of split
for i,conv in enumerate(self.conv):
#print(i,conv(input).size())
output.append(conv(input))
#the part of fusion
U=reduce(lambda x,y:x+y,output) # 逐元素相加生成 混合特征U
s=self.global_pool(U)
z=self.fc1(s) # S->Z降维
a_b=self.fc2(z) # Z->a,b 升维 论文使用conv 1x1表示全连接。结果中前一半通道值为a,后一半为b
a_b=a_b.reshape(batch_size,self.M,self.out_channels,-1) #调整形状,变为 两个全连接层的值
a_b=self.softmax(a_b) # 使得两个全连接层对应位置进行softmax
#the part of selection
a_b=list(a_b.chunk(self.M,dim=1))#split to a and b chunk为pytorch方法,将tensor按照指定维度切分成 几个tensor块
a_b=list(map(lambda x:x.reshape(batch_size,self.out_channels,1,1),a_b)) # 将所有分块 调整形状,即扩展两维
V=list(map(lambda x,y:x*y,output,a_b)) # 权重与对应 不同卷积核输出的U 逐元素相乘
V=reduce(lambda x,y:x+y,V) # 两个加权后的特征 逐元素相加
return V
class SKBlock(nn.Module):
'''
基于Res Block构造的SK Block
ResNeXt有 1x1Conv(通道数:x) + SKConv(通道数:x) + 1x1Conv(通道数:2x) 构成
'''
expansion=2 #指 每个block中 通道数增大指定倍数
def __init__(self,inplanes,planes,stride=1,downsample=None):
super(SKBlock,self).__init__()
self.conv1=nn.Sequential(nn.Conv2d(inplanes,planes,1,1,0,bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True))
self.conv2=SKConv(planes,planes,stride)
self.conv3=nn.Sequential(nn.Conv2d(planes,planes*self.expansion,1,1,0,bias=False),
nn.BatchNorm2d(planes*self.expansion))
self.relu=nn.ReLU(inplace=True)
self.downsample=downsample
def forward(self, input):
shortcut=input
output=self.conv1(input)
output=self.conv2(output)
output=self.conv3(output)
if self.downsample is not None:
shortcut=self.downsample(input)
output+=shortcut
return self.relu(output)
class SKNet(nn.Module):
'''
参考 论文Table.1 进行构造
'''
def __init__(self,nums_class=1000,block=SKBlock,nums_block_list=[3, 4, 6, 3]):
super(SKNet,self).__init__()
self.inplanes=64
# in_channel=3 out_channel=64 kernel=7x7 stride=2 padding=3
self.conv=nn.Sequential(nn.Conv2d(3,64,7,2,3,bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
self.maxpool=nn.MaxPool2d(3,2,1) # kernel=3x3 stride=2 padding=1
self.layer1=self._make_layer(block,128,nums_block_list[0],stride=1) # 构建表中 每个[] 的部分
self.layer2=self._make_layer(block,256,nums_block_list[1],stride=2)
self.layer3=self._make_layer(block,512,nums_block_list[2],stride=2)
self.layer4=self._make_layer(block,1024,nums_block_list[3],stride=2)
self.avgpool=nn.AdaptiveAvgPool2d(1) # GAP全局平均池化
self.fc=nn.Linear(1024*block.expansion,nums_class) # 通道 2048 -> 1000
self.softmax=nn.Softmax(-1) # 对最后一维进行softmax
def forward(self, input):
output=self.conv(input)
output=self.maxpool(output)
output=self.layer1(output)
output=self.layer2(output)
output=self.layer3(output)
output=self.layer4(output)
output=self.avgpool(output)
output=output.squeeze(-1).squeeze(-1)
output=self.fc(output)
output=self.softmax(output)
return output
def _make_layer(self,block,planes,nums_block,stride=1):
downsample=None
if stride!=1 or self.inplanes!=planes*block.expansion:
downsample=nn.Sequential(nn.Conv2d(self.inplanes,planes*block.expansion,1,stride,bias=False),
nn.BatchNorm2d(planes*block.expansion))
layers=[]
layers.append(block(self.inplanes,planes,stride,downsample))
self.inplanes=planes*block.expansion
for _ in range(1,nums_block):
layers.append(block(self.inplanes,planes))
return nn.Sequential(*layers)
def SKNet50(nums_class=1000):
return SKNet(nums_class,SKBlock,[3, 4, 6, 3]) # 论文通过[3, 4, 6, 3]搭配出SKNet50
def SKNet101(nums_class=1000):
return SKNet(nums_class,SKBlock,[3, 4, 23, 3])
if __name__=='__main__':
x = torch.rand(2, 3, 224, 224)
model=SKNet50()
y=model(x)
print(y) # shape [2,1000] 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏