
暑期完成MGCNN类的简化,将其按流程分割
流程
数据处理
数据处理的过程思路
- 对原始数据进行分割处理
- 进行k折交叉验证时将数据分成k份
- k折交叉验证的第i次,取k份中的第i份为验证集,其他部分为训练集
- 每一折的数据读取时,将读取的原始样本数据修改格式为神经网络输入所需要的形状并生成标签y
- 将数组拼接起来形成完整的
train_x, train_labels,test_x, test_labels - 通过
utils.to_categorical将train_labels、test_labels的类别标签转化为onehot编码从而得到train_y,test_y
参数的初始值
#参数初始值
shape = (8192, 1)
channel = shape[1]
feature_length = shape[0]#样本长度
n_classes = None
n_classes = n_classes if n_classes is not None else 0
epochs = 10
batch_size = 100
class_dirs = os.listdir('./data/1024_768_RESAMPLE_1M_1M_FFT')#0文件夹,1的文件夹
data_path='./data/1024_768_RESAMPLE_1M_1M_FFT'
checkpoint_dir = './training/{}-model'.format('test')
checkpoint_filepath_format = os.path.join(checkpoint_dir, 'cp-{epoch:04d}.ckpt')
model_save_file_name = os.path.join(checkpoint_dir, '{}.h5'.format('test'))
csv_logger_dir = './logs/csv'
csvlogger_filepath = os.path.join(csv_logger_dir,'{}.csv'.format('test'))
model=None
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path, class_dir)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
n_classes += 1实现代码
#加载数据
def reshape( file_path, class_label):
sample_x = np.load(file_path)
sample_x = np.reshape(sample_x, (
len(sample_x), feature_length, channel))
sample_y = np.full(len(sample_x), class_label)
return sample_x, sample_y
#随机排列一个序列,返回一个排列的序列。
def permutation(dataset, labels):
permutation = np.random.permutation(labels.shape[0])
shuffled_dataset = dataset[permutation, :, :]
shuffled_labels = labels[permutation]
return shuffled_dataset, shuffled_labels
#k折交叉验证,第i次
def init_alldata(k,i):
logger.info('Start loading data from the path of {}'.format(data_path))
# split_data_by_file_num(k, i)
# init_data初始化数据
train_x = np.empty(shape=[0, feature_length, channel]) # shape(0, 8192, 1)
train_labels = np.empty(shape=[0], dtype=int) # (0,)
test_x = np.empty(shape=[0, feature_length, channel]) # (0,8192,1)
test_labels = np.empty(shape=[0], dtype=int) # (0,)
# print("test shape",train_x.shape,train_labels.shape,test_x.shape,test_labels.shape)
# 分割
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path,class_dir) # ./data/1024_768_RESAMPLE_1M_1M_FFT\0 ./data/1024_768_RESAMPLE_1M_1M_FFT\1
print("sub_dir_path:", sub_dir_path)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
class_index = int(class_dir)
files = sorted(os.listdir(sub_dir_path)) # 里面的所有文件
length = len(files) # 文件数量
each = length // k # 向下取整
print("class_index", class_index, "\n", "files", files, "\nlength", length, "\neach", each)
if i - 1 >= 0:#选k折交叉验证测试集前面部分
for file_name in files[:i * each]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
if i + 1 < k:#省略掉验证集后选k折交叉验证后面部分
for file_name in files[(i + 1) * each:]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
for file_name in files[i * each: (i + 1) * each]:#k折交叉验证的测试集部分
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
test_x = np.concatenate((test_x, sample_x), axis=0)#数组拼接
test_labels = np.concatenate((test_labels, sample_y), axis=0)
train_x, train_labels = permutation(train_x, train_labels)
test_x, test_labels = permutation(test_x, test_labels)
train_y = utils.to_categorical(train_labels, n_classes)#将整型的类别标签转为onehot编码。
test_y = utils.to_categorical(test_labels, n_classes)#将整型的类别标签转为onehot编码。
return train_x, train_labels,test_x, test_labels,train_y,test_y
创建模型
模型创建顺序
- 定义顺序模型
Sequential() - 像模型中隐藏层添加卷积层、激活层、池化层
- 其中可添加
BatchNormalization()批标准化层将分散的数据统一,还可添加Dropout层防止过拟合 - 最后添加上全连接层、设置优化器 后即可编译模型,完成模型的创建
实现代码
#创建模型
def create_model_cnn2_bn(model):
epochs = 10
batch_size = 100
model = Sequential()
model.add(
Conv1D(filters=16, kernel_size=160, strides=4, input_shape=(feature_length, 1), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2))
model.add(
Conv1D(filters=16, kernel_size=12, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2, name='last_conv_layer'))
model.add(Flatten())
model.add(Dense(n_classes, activation='softmax'))
print("n_classesn_classesn_classesn_classesn_classesn_classes",n_classes)
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
print("模型创建成功!!!")
return model训练模型
创建一个callback类的ModelCheckpoint
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)keras的callback类提供了可以跟踪目标值,和动态调整学习效率
该回调函数将在每个epoch后保存模型到filepath
filepath 可以包括命名格式选项,可以由 epoch 的值和 logs 的键(由 on_epoch_end 参数传递)来填充。
参数:
- filepath: 字符串,保存模型的路径。
- monitor: 被监测的数据。val_acc或这val_loss
- verbose: 详细信息模式,0 或者 1 。0为不打印输出信息,1打印
- save_best_only: 如果
save_best_only=True, 将只保存在验证集上性能最好的模型 - mode: {auto, min, max} 的其中之一。 如果
save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于val_acc,模式就会是max,而对于val_loss,模式就需要是min,等等。 在auto模式中,方向会自动从被监测的数据的名字中判断出来。 - save_weights_only: 如果 True,那么只有模型的权重会被保存 (
model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。 - period: 每个检查点之间的间隔(训练轮数)。
# 回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为 callbacks 关键字参数)到 Sequential 或 Model 类型的 .fit() 方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。
ckpt = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath_format,#保存模型的路径。
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
monitor='val_loss',#要监测的量,这里是验证准确率。val_acc或这val_loss
verbose=1,#详细信息模式,0 或者 1 。0为不打印输出信息,1打印
period=5)#每个检查点之间的间隔(训练轮数)。
#创建一个callback类的EarlyStopping
early stop是训练模型的过程中,避免过拟合,节省训练时间的一种非常场用的方法。
在模型训练的过程中,当模型在训练集上表现很好,在验证集上表现很差的时候,此时就认为模型出现了过拟合(overfitting)的情况。
参数:
- monitor: 监控指标,如
val_loss - min_delta: 认为监控指标有提升的最小提升值。如果变化值小于该值,则认为监控指标没有提升。
- patience: 在监控指标没有提升的情况下,epochs 等待轮数。等待大于该值监控指标始终没有提升,则提前停止训练。
- verbose: log输出方式
- mode: 三选一 {“auto”, “min”, “max”},默认auto。min 模式是在监控指标值不再下降时停止训练;max 模式是指在监控指标值不再上升时停止训练;max 模式是指根据 monitor来自动选择。
- baseline: 监控指标需要到达的baseline值。如果监控指标没有到达该值,则提前停止。
- restore_best_weights: 是否加载训练过程中保存的最优模型权重,如果为False,则使用在训练的最后一步获得的模型权重。
earlystop = keras.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=1e-8, patience=5,
verbose=True)
开始训练实现回调
callbacks = [ckpt, csv_logger,earlystop ]#实现回调将callbacks放入model.fit()函数的callback参数中实现回调
实现代码
#训练模型
def model_fit(model):
# 回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为 callbacks 关键字参数)到 Sequential 或 Model 类型的 .fit() 方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。
ckpt = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath_format,#保存模型的路径。
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
monitor='val_loss',#被监测的数据。val_acc或这val_loss
verbose=1,#详细信息模式,0 或者 1 。0为不打印输出信息,1打印
period=5)#每个检查点之间的间隔(训练轮数)。
#
print("checkpoint_filepath_format:", checkpoint_filepath_format)
earlystop = keras.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=1e-8, patience=5,
verbose=True)
csv_logger = keras.callbacks.CSVLogger(csvlogger_filepath, separator=',', append=False)
callbacks = [ckpt, csv_logger,earlystop ]#实现回调
index = -(len(train_x) // 10)
print(index)
print(train_x[:index].shape,"\n" ,train_y[:index].shape)
history = model.fit(train_x[:index], train_y[:index],#模型输入
batch_size=batch_size,
epochs=epochs,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
callbacks=callbacks,
validation_data=(train_x[:index], train_y[:index]))#指定的验证集
model.save(model_save_file_name)
return model, history模型评估
评价指标
常用评价指标
混淆矩阵(Confuse Matrix)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 Score、P-R曲线(Precision-Recall Curve)、ROC、AUC。
混淆矩阵(Confuse Matrix)
针对一个二分类问题,即将实例分成正类(positive)或负类(negative),在实际分类中会出现以下四种情况: (1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive ) (2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative ) (3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive ) (4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative )
混淆矩阵的每一行是样本的预测分类,每一列是样本的真实分类
| 真实标签\预测标签 | 正例 | 反例 |
|---|---|---|
| 正例 | TP(真正类) | FN(假反类) |
| 反例 | FP(假正类) | TN(真反类) |
准确率、精确率、召回率、F1 Score
准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 Score
1.准确率(Accuracy)
预测正确的样本数量占总量的百分比,具体的公式如下:
准确率有一个缺点,就是数据的样本不均衡,这个指标是不能评价模型的性能优劣的。
假如一个测试集有正样本99个,负样本1个。模型把所有的样本都预测为正样本,那么模型的Accuracy为99%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。
2.精准率(Precision)
又称为查准率,是针对预测结果而言的一个评价指标。在模型预测为正样本的结果中,真正是正样本所占的百分比,具体公式如下:
精准率的含义就是在预测为正样本的结果中,有多少是准确的。这个指标比较谨慎,分类阈值较高。
3.召回率(Recall)
又称为查全率,是针对原始样本而言的一个评价指标。在实际为正样本中,被预测为正样本所占的百分比。具体公式如下:
尽量检测数据,不遗漏数据,所谓的宁肯错杀一千,不肯放过一个,分类阈值较低。
4.F1 Score
针对精准率和召回率都有其自己的缺点;如果阈值较高,那么精准率会高,但是会漏掉很多数据;如果阈值较低,召回率高,但是预测的会很不准确。
例子一
假设总共有10个好苹果,10个坏苹果。针对这20个数据,模型只预测了1个好苹果,对应结果如下表

虽然精确率很高,但是这个模型的性能并不好。
例子二
同样总共有10个好苹果,10个坏苹果。针对这20个数据,模型把所有的苹果都预测为好苹果,对应结果如下表
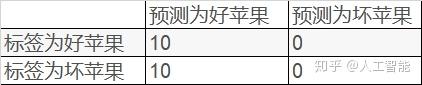
虽然召回率很高,但是这个模型的性能并不好。
从上述例子中,可以看到精确率和召回率是此消彼长的,如果要兼顾二者,就需要F1 Score。
F1 Score是一种调和平均数。
#模型评估
def save_predict(n=0, prediction_y=None, predict_labels=None):
files_name = "./logs/{}_{}_False.csv".format(n, project_name)
name = ['predict_airplane', 'predict_cat', 'predict_label', 'real_label']
csv_data = []
for i in range(len(predict_labels)):
if predict_labels[i] != test_labels[i]:
temp = (prediction_y[i][0], prediction_y[i][1], predict_labels[i], test_labels[i])
csv_data.append(temp)
df = pd.DataFrame(csv_data, columns=name)
df.to_csv(files_name, encoding='utf-8', index=0)
def calculate( predict_labels, test_labels):
logger.info("confusion_matrix")
logger.info(str(metrics.confusion_matrix(test_labels, predict_labels)))
accuracy_score = metrics.accuracy_score(test_labels, predict_labels)
logger.info("accuracy_score:%s", str(accuracy_score))
if n_classes == 2:
precision_score = metrics.precision_score(test_labels, predict_labels)
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels)
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels)
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
else:
precision_score = metrics.precision_score(test_labels, predict_labels, average='micro')
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels, average='micro')
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels, average='micro')
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
pass
mian 入口函数
if __name__ == '__main__':
#创建文件夹los/csv和training/test-model
mkdir_recursively(checkpoint_dir)
mkdir_recursively(csv_logger_dir)
logger = get_logger('mgcnn_airplane_cat')
project_name = 'test'
model=None
k=5
evaluation = []
#k折
for i in range(k):
#加载数据
train_x, train_labels,test_x, test_labels,train_y,test_y=init_alldata(k,i)
#创建模型
model=create_model_cnn2_bn(model)
#训练模型
model_fit(model)
#评价指标
prediction_y = model.predict(test_x)
predict_labels = [np.argmax(one_hot) for one_hot in prediction_y]
save_predict(i, prediction_y, predict_labels)
logger.info("第{}次{}模型评价指标".format(i+1, project_name))
evaluation.append(calculate(predict_labels, test_labels))
evaluation_mean = np.mean(evaluation, 0)
logger.info(evaluation)
logger.info(evaluation_mean)完整代码
import logging
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt #可视化的模块
from sklearn import metrics
from tensorflow import keras
from tensorflow.python.keras import utils
from tensorflow.python.keras import Sequential #按顺序建立的model,一个层建立之后再建立一个层
from tensorflow.python.keras.optimizers import Adam
from tensorflow.python.keras.layers import Conv1D
from tensorflow.python.keras.layers import MaxPooling1D
from tensorflow.python.keras.layers import Flatten
from tensorflow.python.keras.layers import Dense #全连接层
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.layers import BatchNormalization
from tensorflow.python.keras.layers import Activation
import warnings
warnings.filterwarnings('ignore')
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
set_session(sess)
keras.backend.clear_session() #清理session
#参数初始值
shape = (8192, 1)
channel = shape[1]
feature_length = shape[0]#样本长度
n_classes = None
n_classes = n_classes if n_classes is not None else 0
epochs = 10
batch_size = 100
train_x = None
train_labels = None
train_y = None
test_x = None
test_labels = None
test_y = None
class_dirs = os.listdir('./data/1024_768_RESAMPLE_1M_1M_FFT')#0文件夹,1的文件夹
data_path='./data/1024_768_RESAMPLE_1M_1M_FFT'
checkpoint_dir = './training/{}-model'.format('test')
checkpoint_filepath_format = os.path.join(checkpoint_dir, 'cp-{epoch:04d}.ckpt')
model_save_file_name = os.path.join(checkpoint_dir, '{}.h5'.format('test'))
csv_logger_dir = './logs/csv'
csvlogger_filepath = os.path.join(csv_logger_dir,'{}.csv'.format('test'))
model=None
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path, class_dir)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
n_classes += 1
n=0
#日志
def get_logger(log_name):
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DATE_FORMAT = "%m/%d/%Y %H:%M:%S %p" # 日期格式
fp = logging.FileHandler('./{}.log'.format(log_name), encoding='utf-8')
fs = logging.StreamHandler()
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT, datefmt=DATE_FORMAT, handlers=[fp, fs]) # 调用
logger = logging.getLogger(__name__)
return logger
#创建文件夹
def mkdir_recursively(path):
"""
Create the path recursively, same as os.makedirs().
Return True if success, or return False.
e.g.
mkdir_recursively('d:\\a\\b\\c') will create the d:\\a, d:\\a\\b, and d:\\a\\b\\c if these paths does not exist.
"""
log = get_logger('mg-cnn')
# First transform '\\' to '/'
local_path = path.replace('\\', '/')
path_list = local_path.split('/')
print(path_list)
if path_list is None: return False
# For windows, we should add the '\\' at the end of disk name. e.g. C: -> C:\\
disk_name = path_list[0]
if disk_name[-1] == ':': path_list[0] = path_list[0] + '\\'
dir = ''
for path_item in path_list:
dir = os.path.join(dir, path_item)
print
"dir:", dir
if os.path.exists(dir):
if os.path.isdir(dir):
log.debug("mkdir skipped: {}, already exist.".format(dir))
else: # Maybe a regular file, symlink, etc.
log.debug("Invalid directory already exist: {}".format(dir))
return False
else:
try:
os.mkdir(dir)
except Exception as e:
log.error("mkdir error: {}".format(dir))
return False
return True
#加载数据
def reshape( file_path, class_label):
sample_x = np.load(file_path)
sample_x = np.reshape(sample_x, (
len(sample_x), feature_length, channel))
sample_y = np.full(len(sample_x), class_label)
return sample_x, sample_y
#k折交叉验证,第i次
def init_alldata(k,i):
logger.info('Start loading data from the path of {}'.format(data_path))
# split_data_by_file_num(k, i)
# init_data初始化数据
train_x = np.empty(shape=[0, feature_length, channel]) # shape(0, 8192, 1)
train_labels = np.empty(shape=[0], dtype=int) # (0,)
test_x = np.empty(shape=[0, feature_length, channel]) # (0,8192,1)
test_labels = np.empty(shape=[0], dtype=int) # (0,)
# print("test shape",train_x.shape,train_labels.shape,test_x.shape,test_labels.shape)
# 分割
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path,
class_dir) # ./data/1024_768_RESAMPLE_1M_1M_FFT\0 ./data/1024_768_RESAMPLE_1M_1M_FFT\1
print("sub_dir_path:", sub_dir_path)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
class_index = int(class_dir)
files = sorted(os.listdir(sub_dir_path)) # 里面的所有文件
length = len(files) # 文件数量
each = length // k # 向下取整
print("class_index", class_index, "\n", "files", files, "\nlength", length, "\neach", each)
if i - 1 >= 0:#选k折交叉验证测试集前面部分
for file_name in files[:i * each]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
if i + 1 < k:#省略掉验证集后选k折交叉验证后面部分
for file_name in files[(i + 1) * each:]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
for file_name in files[i * each: (i + 1) * each]:#k折交叉验证的测试集部分
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
test_x = np.concatenate((test_x, sample_x), axis=0)#数组拼接
test_labels = np.concatenate((test_labels, sample_y), axis=0)
train_x, train_labels = permutation(train_x, train_labels)
test_x, test_labels = permutation(test_x, test_labels)
train_y = utils.to_categorical(train_labels, n_classes)
test_y = utils.to_categorical(test_labels, n_classes)
return train_x, train_labels,test_x, test_labels,train_y,test_y
#创建模型
def create_model_cnn2_bn(model):
epochs = 10
batch_size = 100
model = Sequential()
model.add(
Conv1D(filters=16, kernel_size=160, strides=4, input_shape=(feature_length, 1), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2))
model.add(
Conv1D(filters=16, kernel_size=12, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2, name='last_conv_layer'))
model.add(Flatten())
model.add(Dense(n_classes, activation='softmax'))
print("n_classesn_classesn_classesn_classesn_classesn_classes",n_classes)
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
print("模型创建成功!!!")
return model
#训练模型
def model_fit(model):
# 回调函数是一个函数的合集,会在训练的阶段中所使用。你可以使用回调函数来查看训练模型的内在状态和统计。你可以传递一个列表的回调函数(作为 callbacks 关键字参数)到 Sequential 或 Model 类型的 .fit() 方法。在训练时,相应的回调函数的方法就会被在各自的阶段被调用。
ckpt = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath_format,#保存模型的路径。
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
monitor='val_loss',#被监测的数据。val_acc或这val_loss
verbose=1,#详细信息模式,0 或者 1 。0为不打印输出信息,1打印
period=5)#每个检查点之间的间隔(训练轮数)。
#
print("checkpoint_filepath_format:", checkpoint_filepath_format)
earlystop = keras.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=1e-8, patience=5,
verbose=True)
csv_logger = keras.callbacks.CSVLogger(csvlogger_filepath, separator=',', append=False)
callbacks = [ckpt, csv_logger,earlystop ]#实现回调
index = -(len(train_x) // 10)
print(index)
print(train_x[:index].shape,"\n" ,train_y[:index].shape)
history = model.fit(train_x[:index], train_y[:index],#模型输入
batch_size=batch_size,
epochs=epochs,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
callbacks=callbacks,
validation_data=(train_x[:index], train_y[:index]))#指定的验证集
model.save(model_save_file_name)
return model, history
#模型评估
def save_predict(n=0, prediction_y=None, predict_labels=None):
files_name = "./logs/{}_{}_False.csv".format(n, project_name)
name = ['predict_airplane', 'predict_cat', 'predict_label', 'real_label']
csv_data = []
for i in range(len(predict_labels)):
if predict_labels[i] != test_labels[i]:
temp = (prediction_y[i][0], prediction_y[i][1], predict_labels[i], test_labels[i])
csv_data.append(temp)
df = pd.DataFrame(csv_data, columns=name)
df.to_csv(files_name, encoding='utf-8', index=0)
def calculate( predict_labels, test_labels):
logger.info("confusion_matrix")
logger.info(str(metrics.confusion_matrix(test_labels, predict_labels)))
accuracy_score = metrics.accuracy_score(test_labels, predict_labels)
logger.info("accuracy_score:%s", str(accuracy_score))
if n_classes == 2:
precision_score = metrics.precision_score(test_labels, predict_labels)
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels)
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels)
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
else:
precision_score = metrics.precision_score(test_labels, predict_labels, average='micro')
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels, average='micro')
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels, average='micro')
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
pass
def permutation(dataset, labels):
permutation = np.random.permutation(labels.shape[0])
shuffled_dataset = dataset[permutation, :, :]
shuffled_labels = labels[permutation]
return shuffled_dataset, shuffled_labels
if __name__ == '__main__':
#创建文件夹los/csv和training/test-model
mkdir_recursively(checkpoint_dir)
mkdir_recursively(csv_logger_dir)
logger = get_logger('mgcnn_airplane_cat')
project_name = 'test'
model=None
k=5
evaluation = []
#k折
for i in range(k):
#加载数据
train_x, train_labels,test_x, test_labels,train_y,test_y=init_alldata(k,i)
#创建模型
model=create_model_cnn2_bn(model)
#训练模型
model_fit(model)
#评价指标
prediction_y = model.predict(test_x)
predict_labels = [np.argmax(one_hot) for one_hot in prediction_y]
save_predict(i, prediction_y, predict_labels)
logger.info("第{}次{}模型评价指标".format(i+1, project_name))
evaluation.append(calculate(predict_labels, test_labels))
evaluation_mean = np.mean(evaluation, 0)
logger.info(evaluation)
logger.info(evaluation_mean)import logging
import os
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt #可视化的模块
from sklearn import metrics
from tensorflow import keras
from tensorflow.python.keras import utils
from tensorflow.python.keras import Sequential #按顺序建立的model,一个层建立之后再建立一个层
from tensorflow.python.keras.optimizers import Adam
from tensorflow.python.keras.layers import Conv1D
from tensorflow.python.keras.layers import MaxPooling1D
from tensorflow.python.keras.layers import Flatten
from tensorflow.python.keras.layers import Dense #全连接层
from tensorflow.python.keras.layers import Dropout
from tensorflow.python.keras.layers import BatchNormalization
from tensorflow.python.keras.layers import Activation
import warnings
warnings.filterwarnings('ignore')
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
set_session(sess)
keras.backend.clear_session() #清理session
#参数初始值
shape = (8192, 1)
channel = shape[1]
feature_length = shape[0]#样本长度
n_classes = None
n_classes = n_classes if n_classes is not None else 0
epochs = 10
batch_size = 100
train_x = None
train_labels = None
train_y = None
test_x = None
test_labels = None
test_y = None
class_dirs = os.listdir('./data/1024_768_RESAMPLE_1M_1M_FFT')#0文件夹,1的文件夹
data_path='./data/1024_768_RESAMPLE_1M_1M_FFT'
checkpoint_dir = './training/{}-model'.format('test')
checkpoint_filepath_format = os.path.join(checkpoint_dir, 'cp-{epoch:04d}.ckpt')
model_save_file_name = os.path.join(checkpoint_dir, '{}.h5'.format('test'))
csv_logger_dir = './logs/csv'
csvlogger_filepath = os.path.join(csv_logger_dir,'{}.csv'.format('test'))
model=None
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path, class_dir)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
n_classes += 1
n=0
#日志
def get_logger(log_name):
LOG_FORMAT = "%(asctime)s - %(levelname)s - %(message)s"
DATE_FORMAT = "%m/%d/%Y %H:%M:%S %p" # 日期格式
fp = logging.FileHandler('./{}.log'.format(log_name), encoding='utf-8')
fs = logging.StreamHandler()
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT, datefmt=DATE_FORMAT, handlers=[fp, fs]) # 调用
logger = logging.getLogger(__name__)
return logger
#创建文件夹
def mkdir_recursively(path):
"""
Create the path recursively, same as os.makedirs().
Return True if success, or return False.
e.g.
mkdir_recursively('d:\\a\\b\\c') will create the d:\\a, d:\\a\\b, and d:\\a\\b\\c if these paths does not exist.
"""
log = get_logger('mg-cnn')
# First transform '\\' to '/'
local_path = path.replace('\\', '/')
path_list = local_path.split('/')
print(path_list)
if path_list is None: return False
# For windows, we should add the '\\' at the end of disk name. e.g. C: -> C:\\
disk_name = path_list[0]
if disk_name[-1] == ':': path_list[0] = path_list[0] + '\\'
dir = ''
for path_item in path_list:
dir = os.path.join(dir, path_item)
print
"dir:", dir
if os.path.exists(dir):
if os.path.isdir(dir):
log.debug("mkdir skipped: {}, already exist.".format(dir))
else: # Maybe a regular file, symlink, etc.
log.debug("Invalid directory already exist: {}".format(dir))
return False
else:
try:
os.mkdir(dir)
except Exception as e:
log.error("mkdir error: {}".format(dir))
return False
return True
#加载数据
def reshape( file_path, class_label):
sample_x = np.load(file_path)
sample_x = np.reshape(sample_x, (
len(sample_x), feature_length, channel))
sample_y = np.full(len(sample_x), class_label)
return sample_x, sample_y
#随机排列一个序列,返回一个排列的序列。
def permutation(dataset, labels):
permutation = np.random.permutation(labels.shape[0])
shuffled_dataset = dataset[permutation, :, :]
shuffled_labels = labels[permutation]
return shuffled_dataset, shuffled_labels
#k折交叉验证,第i次
def init_alldata(k,i):
logger.info('Start loading data from the path of {}'.format(data_path))
# split_data_by_file_num(k, i)
# init_data初始化数据
train_x = np.empty(shape=[0, feature_length, channel]) # shape(0, 8192, 1)
train_labels = np.empty(shape=[0], dtype=int) # (0,)
test_x = np.empty(shape=[0, feature_length, channel]) # (0,8192,1)
test_labels = np.empty(shape=[0], dtype=int) # (0,)
# print("test shape",train_x.shape,train_labels.shape,test_x.shape,test_labels.shape)
# 分割
for class_dir in class_dirs:
sub_dir_path = os.path.join(data_path,
class_dir) # ./data/1024_768_RESAMPLE_1M_1M_FFT\0 ./data/1024_768_RESAMPLE_1M_1M_FFT\1
print("sub_dir_path:", sub_dir_path)
if os.path.isdir(sub_dir_path) and class_dir.isdigit():
class_index = int(class_dir)
files = sorted(os.listdir(sub_dir_path)) # 里面的所有文件
length = len(files) # 文件数量
each = length // k # 向下取整
print("class_index", class_index, "\n", "files", files, "\nlength", length, "\neach", each)
if i - 1 >= 0:#选k折交叉验证测试集前面部分
for file_name in files[:i * each]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
if i + 1 < k:#省略掉验证集后选k折交叉验证后面部分
for file_name in files[(i + 1) * each:]:
print(("file_name", file_name, "\n"))
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
train_x = np.concatenate((train_x, sample_x), axis=0)
train_labels = np.concatenate((train_labels, sample_y), axis=0)
for file_name in files[i * each: (i + 1) * each]:#k折交叉验证的测试集部分
sample_x, sample_y = reshape(os.path.join(sub_dir_path, file_name), class_index)
test_x = np.concatenate((test_x, sample_x), axis=0)#数组拼接
test_labels = np.concatenate((test_labels, sample_y), axis=0)
train_x, train_labels = permutation(train_x, train_labels)
test_x, test_labels = permutation(test_x, test_labels)
train_y = utils.to_categorical(train_labels, n_classes)
test_y = utils.to_categorical(test_labels, n_classes)
return train_x, train_labels,test_x, test_labels,train_y,test_y
#创建模型
def create_model_cnn2_bn(model):
epochs = 10
batch_size = 100
model = Sequential()
model.add(
Conv1D(filters=16, kernel_size=160, strides=4, input_shape=(feature_length, 1), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2))
model.add(
Conv1D(filters=16, kernel_size=12, strides=2, padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(MaxPooling1D(pool_size=2, name='last_conv_layer'))
model.add(Flatten())
model.add(Dense(n_classes, activation='softmax'))
print("n_classesn_classesn_classesn_classesn_classesn_classes",n_classes)
opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=opt,
metrics=['accuracy'])
print("模型创建成功!!!")
return model
#训练模型
def model_fit(model):
ckpt = keras.callbacks.ModelCheckpoint(
filepath=checkpoint_filepath_format,
# Path where to save the model
# The two parameters below mean that we will overwrite
# the current checkpoint if and only if
# the `val_loss` score has improved.
monitor='val_loss',
verbose=1,
period=5)
#
print("checkpoint_filepath_format:", checkpoint_filepath_format)
earlystop = keras.callbacks.EarlyStopping(
monitor='val_loss',
min_delta=1e-8, patience=5,
verbose=True)
csv_logger = keras.callbacks.CSVLogger(csvlogger_filepath, separator=',', append=False)
callbacks = [ckpt, csv_logger,earlystop ]
index = -(len(train_x) // 10)
print(index)
print(train_x[:index].shape,"\n" ,train_y[:index].shape)
history = model.fit(train_x[:index], train_y[:index],
batch_size=batch_size,
epochs=epochs,
# We pass some validation for
# monitoring validation loss and metrics
# at the end of each epoch
callbacks=callbacks,
validation_data=(train_x[:index], train_y[:index]))
model.save(model_save_file_name)
return model, history
#模型评估
def save_predict(n=0, prediction_y=None, predict_labels=None):
files_name = "./logs/{}_{}_False.csv".format(n, project_name)
name = ['predict_airplane', 'predict_cat', 'predict_label', 'real_label']
csv_data = []
for i in range(len(predict_labels)):
if predict_labels[i] != test_labels[i]:
temp = (prediction_y[i][0], prediction_y[i][1], predict_labels[i], test_labels[i])
csv_data.append(temp)
df = pd.DataFrame(csv_data, columns=name)
df.to_csv(files_name, encoding='utf-8', index=0)
def calculate( predict_labels, test_labels):
logger.info("confusion_matrix")
logger.info(str(metrics.confusion_matrix(test_labels, predict_labels)))
accuracy_score = metrics.accuracy_score(test_labels, predict_labels)
logger.info("accuracy_score:%s", str(accuracy_score))
if n_classes == 2:
precision_score = metrics.precision_score(test_labels, predict_labels)
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels)
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels)
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
else:
precision_score = metrics.precision_score(test_labels, predict_labels, average='micro')
logger.info("precision_score:%s", str(precision_score))
recall_score = metrics.recall_score(test_labels, predict_labels, average='micro')
logger.info("recall_score:%s", str(recall_score))
f1_score = metrics.f1_score(test_labels, predict_labels, average='micro')
logger.info("f1_score:%s", str(f1_score))
return accuracy_score, precision_score, recall_score, f1_score
pass
if __name__ == '__main__':
#创建文件夹los/csv和training/test-model
mkdir_recursively(checkpoint_dir)
mkdir_recursively(csv_logger_dir)
logger = get_logger('mgcnn_airplane_cat')
project_name = 'test'
model=None
k=5
evaluation = []
#k折
for i in range(k):
#加载数据
train_x, train_labels,test_x, test_labels,train_y,test_y=init_alldata(k,i)
#创建模型
model=create_model_cnn2_bn(model)
#训练模型
model_fit(model)
#评价指标
prediction_y = model.predict(test_x)
predict_labels = [np.argmax(one_hot) for one_hot in prediction_y]
save_predict(i, prediction_y, predict_labels)
logger.info("第{}次{}模型评价指标".format(i+1, project_name))
evaluation.append(calculate(predict_labels, test_labels))
evaluation_mean = np.mean(evaluation, 0)
logger.info(evaluation)
logger.info(evaluation_mean)实例化MGCNN
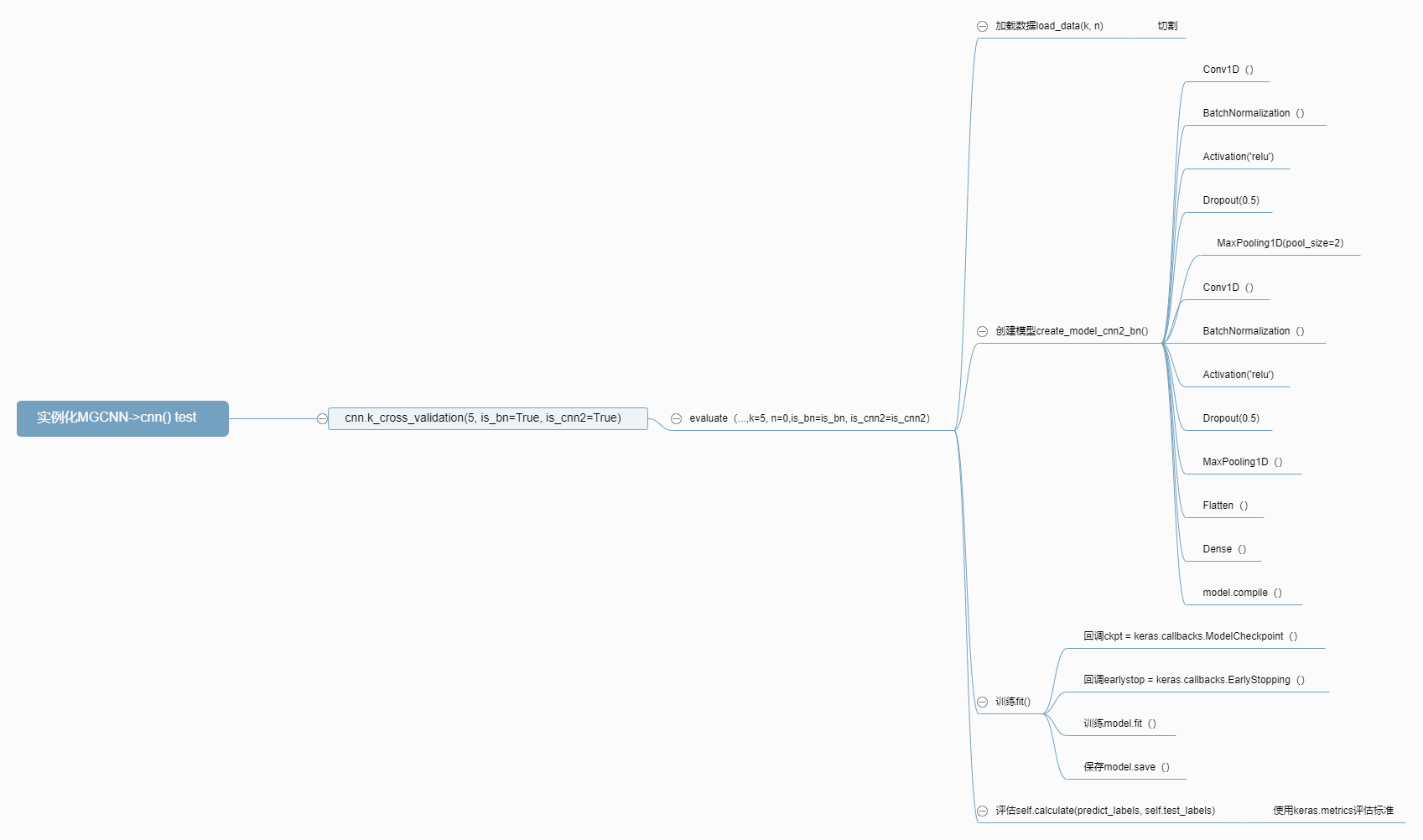
- 实例化
MGCNN->cnn() test
调用k_cross_validation评估
- 调用k_cross_validation评估,算出evaluation和其平均值返回后日志中输出
-
def k_cross_validation(self, k=5, is_bn=False, is_cnn2=False): evaluation = [] for i in range(k): evaluation.append(self.evaluate('{}-第{}/{}折评估指标'.format(self.project_name,str(i + 1), str(k)), k, i, is_bn=is_bn, is_cnn2=is_cnn2)) plt.close() evaluation_mean = np.mean(evaluation, 0) return evaluation, evaluation_mean
-
调用evaluate评估
k_cross_validation中调用evaluate进行评估-
def evaluate(self, project_name, k=5, n=0, is_bn=False, is_cnn2=False): self.load_data(k, n)#加载数据 split_data_by_file_num if is_bn: if is_cnn2: self.create_model_cnn2_bn() else: self.create_model_cnn1_bn() else: if is_cnn2: self.create_model_cnn2() else: self.create_model_cnn1()#调用 self.fit() prediction_y = self.model.predict(self.test_x) predict_labels = [np.argmax(one_hot) for one_hot in prediction_y] self.save_predict(n, prediction_y, predict_labels) logger.info("第{}次{}模型评价指标".format(n, project_name)) return self.calculate(predict_labels, self.test_labels) pass
-
加载数据load_data()
load_data()加载数据->分割数据(k,n)
创建模型
create_model_cnn2_bndef create_model_cnn2_bn(self): self.epochs = 10 self.batch_size = 100 self.model = Sequential() self.model.add( Conv1D(filters=16, kernel_size=160, strides=4, input_shape=(self.feature_length, 1), padding='same')) self.model.add(BatchNormalization())#批标准化层 self.model.add(Activation('relu')) self.model.add(Dropout(0.5)) self.model.add(MaxPooling1D(pool_size=2)) self.model.add( Conv1D(filters=16, kernel_size=12, strides=2, padding='same')) self.model.add(BatchNormalization()) self.model.add(Activation('relu')) self.model.add(Dropout(0.5)) self.model.add(MaxPooling1D(pool_size=2, name='last_conv_layer')) self.model.add(Flatten()) self.model.add(Dense(self.n_classes, activation='softmax')) opt = Adam(lr=0.0001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False) self.model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) pass
训练fit()
- 调用fit训练,并保存到
self.model_save_file_namedef fit(self): # log_dir = os.path.join( # "logs", # "fit", # self.project_name, # ) # # tensorborad = keras.callb acks.TensorBoard( # log_dir=log_dir, # histogram_freq=1, # write_graph=True) #回调函数每一次epoch(period=5)保存最好的参数 ckpt = keras.callbacks.ModelCheckpoint( filepath=self.checkpoint_filepath_format, # Path where to save the model # The two parameters below mean that we will overwrite # the current checkpoint if and only if # the `val_loss` score has improved. monitor='val_loss', verbose=1, period=5) # earlystop = keras.callbacks.EarlyStopping( monitor='val_loss', min_delta=1e-8, patience=5, verbose=True) csv_logger = keras.callbacks.CSVLogger(self.csvlogger_filepath, separator=',', append=False) callbacks = [ckpt, csv_logger,earlystop ] index = -(len(self.train_x) // 10) history = self.model.fit(self.train_x[:index], self.train_y[:index], batch_size=self.batch_size, epochs=self.epochs, # We pass some validation for # monitoring validation loss and metrics # at the end of each epoch callbacks=callbacks, validation_data=(self.train_x[index:], self.train_y[index:])) self.model.save(self.model_save_file_name) return self.model, history pass
模型评估calculate()
- 返回prediction_y和
predict_labels并调用calculate(predict_labels, self.test_labels)其使用keras.metrics评估标准def calculate(self, predict_labels, test_labels): logger.info("confusion_matrix") logger.info(str(metrics.confusion_matrix(test_labels, predict_labels))) accuracy_score = metrics.accuracy_score(test_labels, predict_labels) logger.info("accuracy_score:%s", str(accuracy_score)) if self.n_classes == 2: precision_score = metrics.precision_score(test_labels, predict_labels) logger.info("precision_score:%s", str(precision_score)) recall_score = metrics.recall_score(test_labels, predict_labels) logger.info("recall_score:%s", str(recall_score)) f1_score = metrics.f1_score(test_labels, predict_labels) logger.info("f1_score:%s", str(f1_score)) return accuracy_score, precision_score, recall_score, f1_score else: precision_score = metrics.precision_score(test_labels, predict_labels, average='micro') logger.info("precision_score:%s", str(precision_score)) recall_score = metrics.recall_score(test_labels, predict_labels, average='micro') logger.info("recall_score:%s", str(recall_score)) f1_score = metrics.f1_score(test_labels, predict_labels, average='micro') logger.info("f1_score:%s", str(f1_score)) return accuracy_score, precision_score, recall_score, f1_score pass
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏