
汇报ppt
CAM论文
Grad-CAM论文
卷积神经网络
卷积神经网络工作原理
卷积
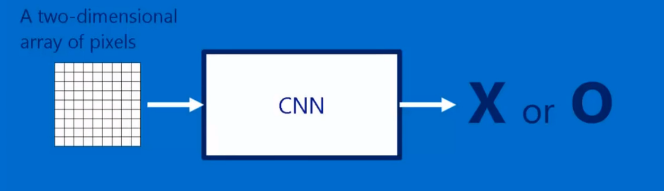
卷积神经网络 是一个函数或者说是黑箱
有输入有输出
输入就是二维像素阵列(图片)
输入就是这个图片是啥 分类结果等
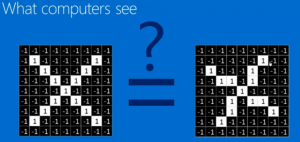
对计算机来说看到的就是像素阵列 灰度图
比如我们将图中的每个像素小方块填上-1和1两种数字,假设图片是黑白的,黑色用-1表示,白色用1表示,那么由计算机识别左图和右图,计算机会认为它们不是一样的,因为左图上某一位置的1或者-1在右图同一位置上不是相同的数字。
特征–》卷积核、特征提取器
future map(特征图)
在图像矩阵中依次取卷积核大小的矩阵(3*3)和卷积核作内积,得到的内积和取平均值,填入新的矩阵中,新矩阵被称为Feature Map
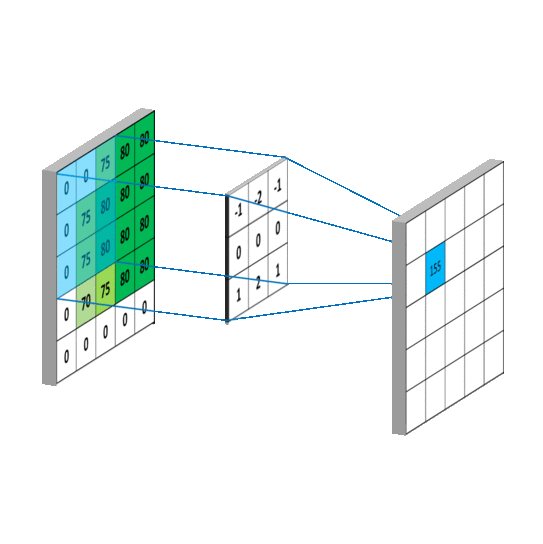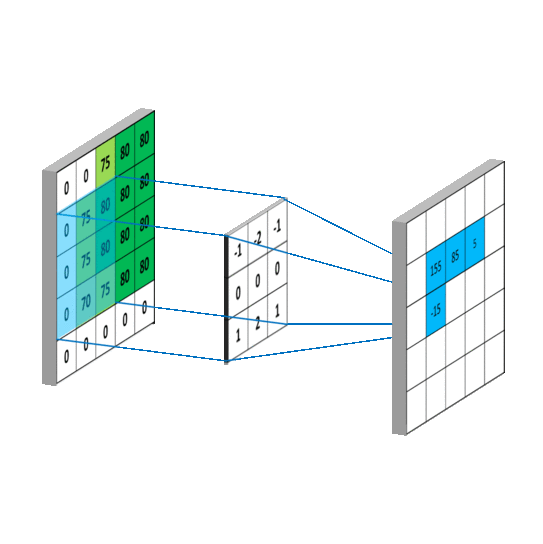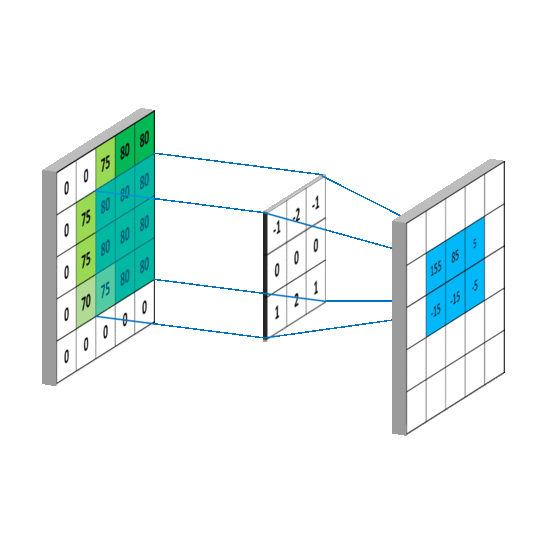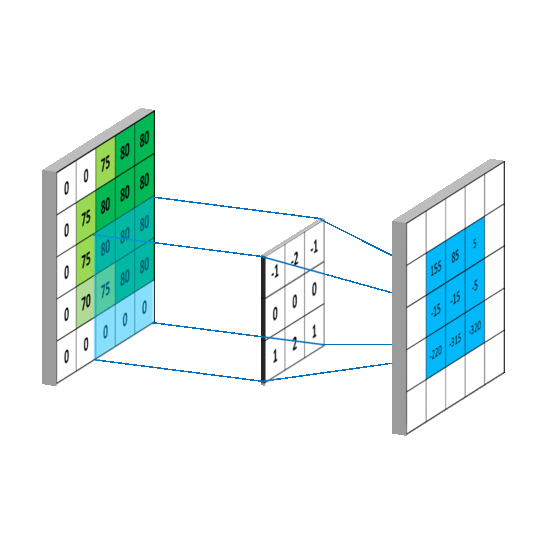
池化
池化 pooling(下采样) (多个像素阵列缩小为1个)池化虽然会使得图像变得模糊但不影响图像的辨认跟位置判断
如人脸特征很多 几万个特征生成几万个future map计算量很大,自动驾驶啥的来不及;
池化–>平移不变性 —– 但是也丢失了空间信息(丢失了长宽方向的位置信息)
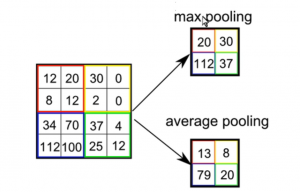
max pooling
average pooling

激活
激活函数 relu(修正线性单元)future map中大于0为本身,小于0 抹0
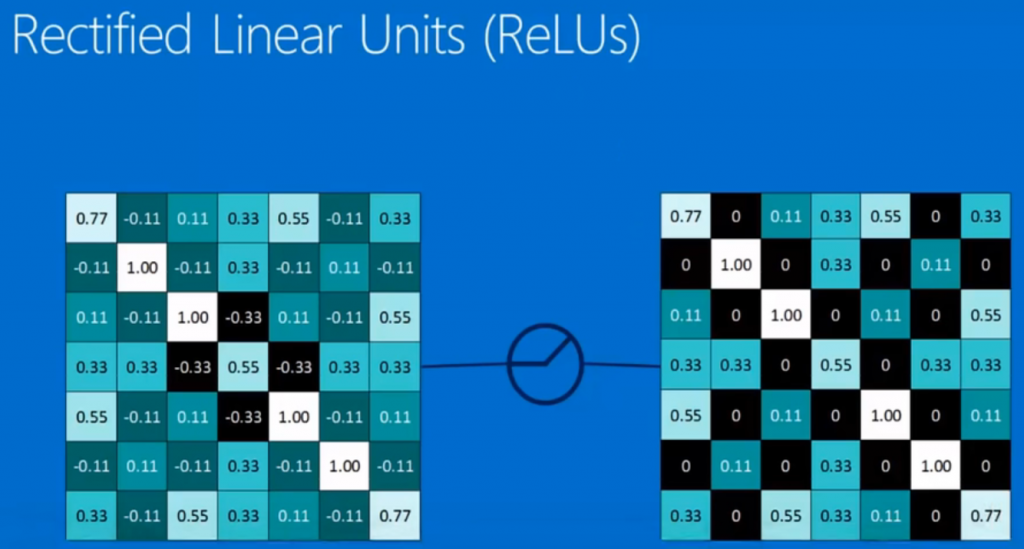
全连接层
汇总前面的所有特征
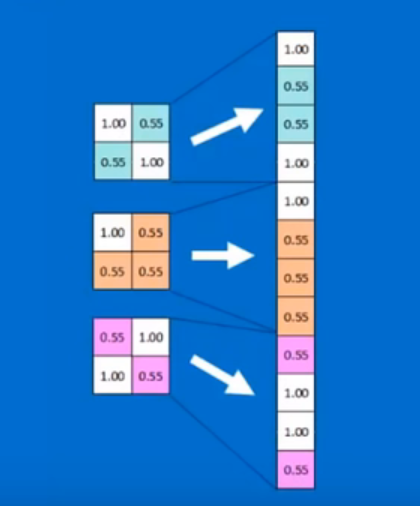
判断是x还是o
排成1列,每个值都有权重,各自乘以对应的权重加起来就能判断出是x的概率是多少
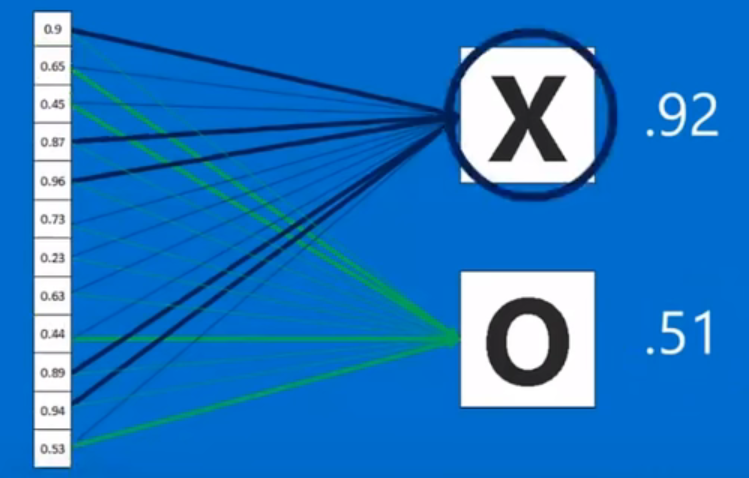
为什么叫全连接—和之前每一个神经元都相连

全连接可以放很多层 叫隐藏层

损失函数、梯度下降、反向传播
梯度下降与反向传播
梯度下降 是 找损失函数极小值的一种方法,
反向传播 是 求解梯度的一种方法。
反向传播 Backpropagation
损失函数 神经网络得到的结果和真实结果进行误差计算
将损失函数降低到最低,求导 调参
一层一层往上传到上去的
大量数据学习后 最后自动学会了采用哪个卷积核
梯度下降将损失函数降到最低
关于损失函数:
在训练阶段,深度神经网络经过前向传播之后,得到的预测值与先前给出真实值之间存在差距。我们可以使用损失函数来体现这种差距。损失函数的作用可以理解为:当前向传播得到的预测值与真实值接近时,取较小值。反之取值增大。并且,损失函数应是以参数(w 权重, b 偏置)为自变量的函数。
训练神经网络,“训练”的含义:
它是指通过输入大量训练数据,使得神经网络中的各参数(w 权重, b 偏置)不断调整“学习”到一个合适的值。使得损失函数最小。
如何训练?
采用 梯度下降 的方式,一点点地调整参数,找损失函数的极小值(最小值)
为啥用梯度下降?
由浅入深,我们最容易想到的调整参数(权重和偏置)是穷举。即取遍参数的所有可能取值,比较在不同取值情况下得到的损失函数的值,即可得到使损失函数取值最小时的参数值。然而这种方法显然是不可取的。因为在深度神经网络中,参数的数量是一个可怕的数字,动辄上万,十几万。并且,其取值有时是十分灵活的,甚至精确到小数点后若干位。若使用穷举法,将会造成一个几乎不可能实现的计算量。
第二个想到的方法就是微分求导。通过将损失函数进行全微分,取全微分方程为零或较小的点,即可得到理想参数。(补充:损失函数取下凸函数,才能使得此方法可行。现实中选取的各种损失函数大多也正是如此。)可面对神经网络中庞大的参数总量,纯数学方法几乎是不可能直接得到微分零点的。
因此我们使用了梯度下降法。既然无法直接获得该点,那么我们就想要一步一步逼近该点。一个常见的形象理解是,爬山时一步一步朝着坡度最陡的山坡往下,即可到达山谷最底部。(至于为何不能闪现到谷底,原因是参数数量庞大,表达式复杂,无法直接计算)我们都知道,向量场的梯度指向的方向是其函数值上升最快的方向,也即其反方向是下降最快的方向。计算梯度的方式就是求偏导。
这里需要引入一个步长的概念。个人理解是:此梯度对参数当前一轮学习的影响程度。步长越大,此梯度影响越大。若以平面直角坐标系中的函数举例,若初始参数x=10,步长为1 。那么参数需要调整十次才能到达谷底。若步长为5,则只需2次。若为步长为11,则永远无法到达真正的谷底。
[5分钟深度学习] #01 梯度下降算法哔哩哔哩bilibili
综合示例

- 将图转换为像素点
- 对原图进行6个卷积生成6个future map
- 对6个future map下采样得到6个小图
- 对小图再卷积,再下采样
- 接着进行两层全连接层
(YouTube视频 How Convolutional Neural Networks work – YouTube
卷积神经网络
将图像拆分成对应的特点,被称为卷积核。然后查看被识别图像有无对应的卷积核来确认是否为目标物体。
用卷积核扫描目标图得出的一个二维图为特征图。
但是这样的话,岂不是有多少个卷积核就要扫描多少遍?
对于一个有大量细节,或者说相当数量分层级的细节来说,这样算法的复杂度是很高的。
所以有池化(pooling)。即缩小特征图(Feature Map)
有最大池化:选择被扫描区域内的最大值
和平均池化:取被扫描区域内的平均值 等池化方式
在处理边缘时的操作称为(Padding)zero padding(周围补0)
如果对图像采用最大池化,则在边缘补零来提取边缘特征
池化要求一定要保留原特征图的特征
卷积计算中的一个基本流程为:卷积,ReLU(修正线性单元),池化(下采样)
然后把得到的最简单的特征图们展开得到一条特征数组(?)
然后就是全链接的操作,对数组按目标图的数组权值操作得到一个判断是否为目标的概率数。
用大数据修正卷积核和全链接的行为叫机器学习
然后用反向传播(backpropagation)的算法不断修正用来处理特征数组的权链接。
得到越来越令人满意的网络。
所以甚至一开始的卷积核和权链接是随机的,只要给出的数据和反馈足够多
仍然可以得到正确的算法网络
可视化卷积神经网络
CS231N斯坦福计算机视觉公开课第六讲
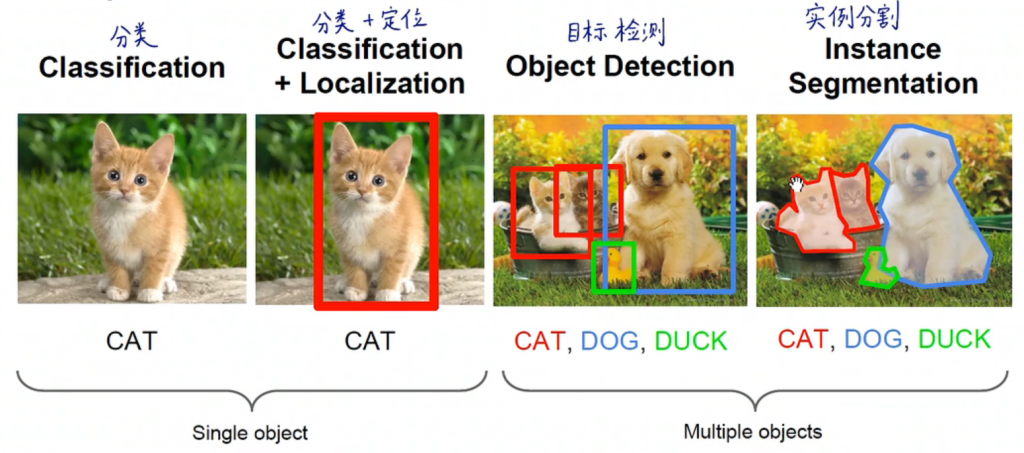
单个图的框:分类急+定位
多个图的框:目标检测
像素级别的抠图:语义分割、实例分割
Cam类激活热力图
cam精妙之处
- 1.对深度学习实现可解释性分析、显著性分析
- 2.可扩展性强,后续衍生出各种基于CAM的算法
- 3.每张图片、每个类别,都能生成CAM热力图
- 4.弱监督定位︰图像分类模型解决定位问题
- 5.潜在的“注意力机制”
- 按权重排序可得特征重要度,辅助Machine Teaching
Cam算法原理
核心插图
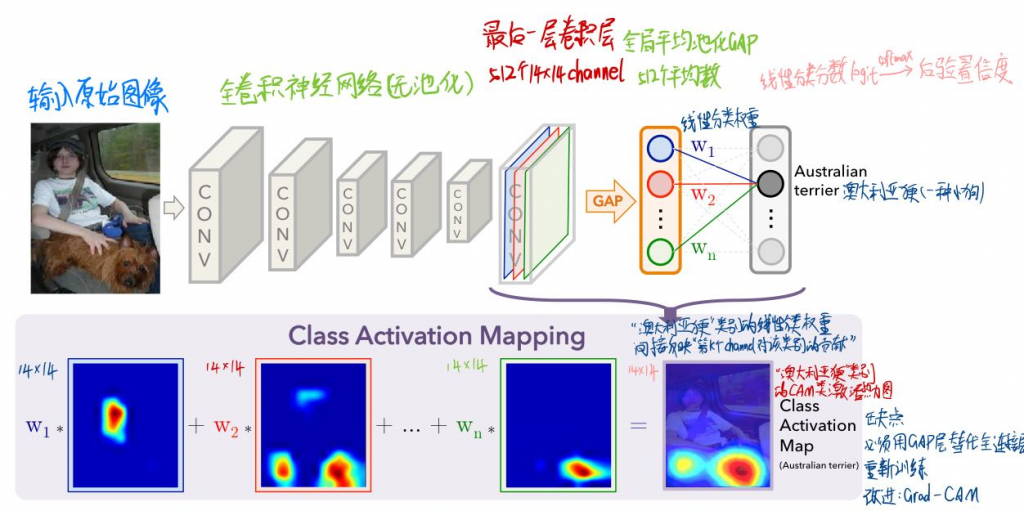
为什么用全卷积网络?
池化–>平移不变性 —– 但是也丢失了空间信息(丢失了长宽方向的位置信息)
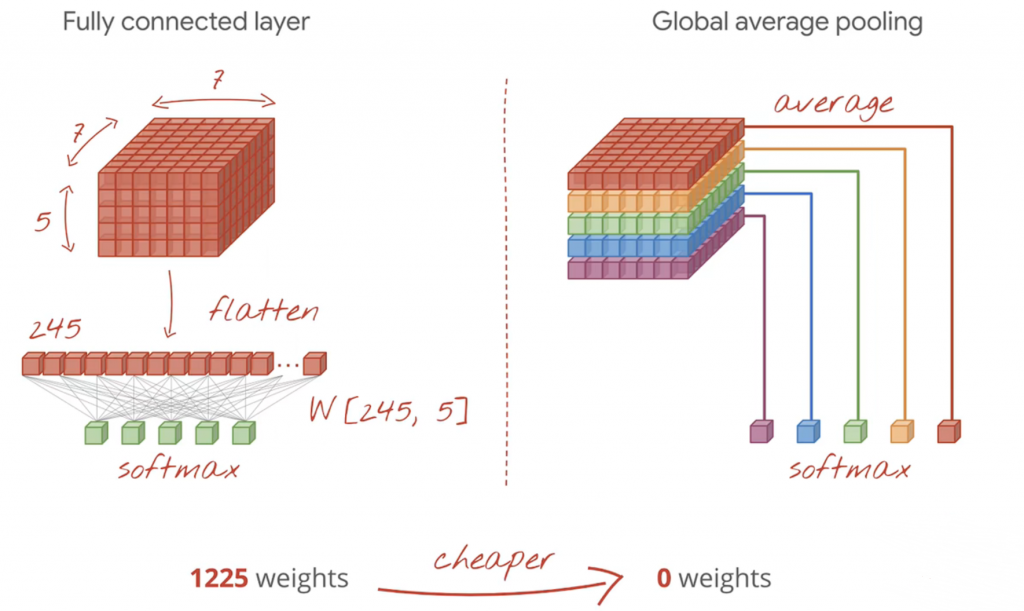
全局平均池化(GAP)
- 全局平均池化(GAP)取代全连接层
- 减少参数量、防止过拟合
- 而且每个GAP平均值,间接代表了卷积层最后一层输出的每个channel
为什么是averge而不是max?
max是取最大值,只是边缘点而非物体范围
averge是关键区域范围内的特征都有影响
而max则是非最大值的特征怎么变化都没用(无梯度)
缺点
- CAM算法中,必须有GAP层,否则无法计算每个channel的权重,如果没有GAP层,需把全连接层替换为GAP再重新训练模型(用Grad-CAM改进)
- 只能分析最后一层卷积层输出,无法分析中间层
- 仅限图像分类任务
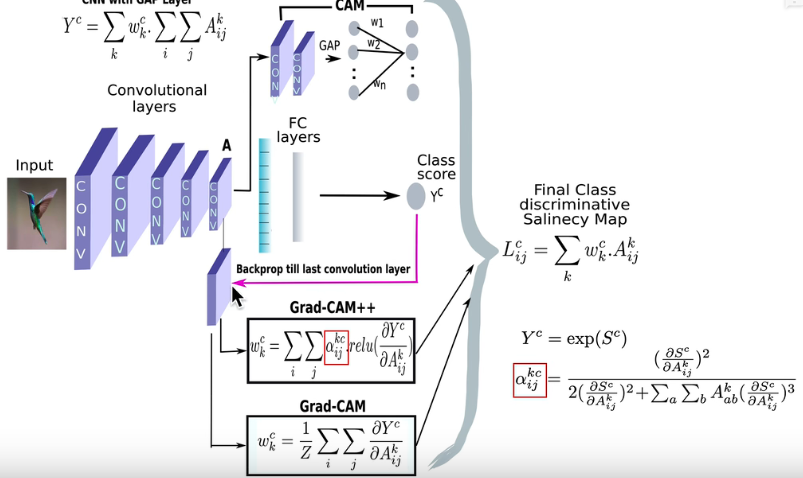
Grad—CAM
算法原理
核心插图
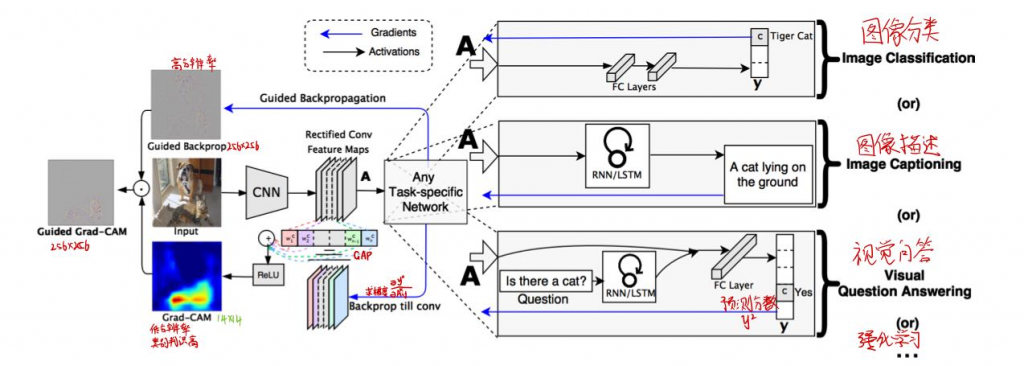
首先网络进行正向传播,得到特征层A(一般指的是最后一个卷积层的输出)和网络预测值y (注意,这里指的是softmax激活之前的数值)。假设我们想看下网络针对Tiger Cat这个类别的感兴趣区域,假设网络针对Tiger Cat类别的预测值为y^c。接着对 y^c进行反向传播,能够得到反传回特征层A的梯度信息Aˊ。通过计算得到针对特征层A每个通道的重要程度,然后进行加权求和通过ReLU就行了,最终得到的结果即是Grad-CAM。
全连接层后预测出每个类别对应的分数y的c次方,改变yc上一层512×14×14的feature map中每一个数值A(i,j)就能知道其对最终预测分数yc的影响,使得yc对每一个A(i,j)求偏导也能获得512×14×14的channel,每个不同channel求平均得到GAP各自的权重
首先得到的特征层A 是网络对原图进行特征提取得到的结果,越往后的特征层抽象程度越高,语义信息越丰富,而且利用CNN抽取得到的特征图是能够保留空间信息的(Transformer同样)。所以Grad-CAM在CNN中一般A都指的是最后一个卷积层的输出。当然特征层A包含了所有我们感兴趣目标的语义信息
兼容各项任务
Guided Backprop
每一个像素对原图的影响—->得到高分辨率图(细粒度)
类别判别性弱
与Grad-CAM逐元素做乘法获得高分辨率又高类别判别能力的热力图
为什么要过ReLU激活函数?
实验表明效果跟好
可以过滤无关信息
有0使得与guided backprop乘法方便
优点
- 无需GAP层,无需修改模型结构,无需重新训练
- 可分析任意中间层
- 数学上是原生CAM的推广
- 细粒度图形分类、Machine Teaching
- 包含Cam优点
- 1.对深度学习实现可解释性分析、显著性分析
- 2.可扩展性强,后续衍生出各种基于CAM的算法
- 3.每张图片、每个类别,都能生成CAM热力图
- 4.弱监督定位︰图像分类模型解决定位问题
- 5.潜在的“注意力机制”
- 按权重排序可得特征重要度,辅助Machine Teaching
缺点
- 图像上由多个同类物体时,只能画出一块热力图
- 不同位置的梯度值,GAP平均之后,影响是相同的
- 梯度饱和、梯度消失、梯度噪声
- 权重大的channel,不一定对类别预测分数贡献大
- 只考虑从后往前的反向传播梯度,没考虑前向预测的影响
- 深层生成的粗粒度热力图和浅层生成的细粒度热力图 都不够精准
后续算法—–Grad-CAM++
解决了前两个问题
- 图像上由多个同类物体时,只能画出一块热力图
- 不同位置的梯度值,GAP平均之后,影响是相同的
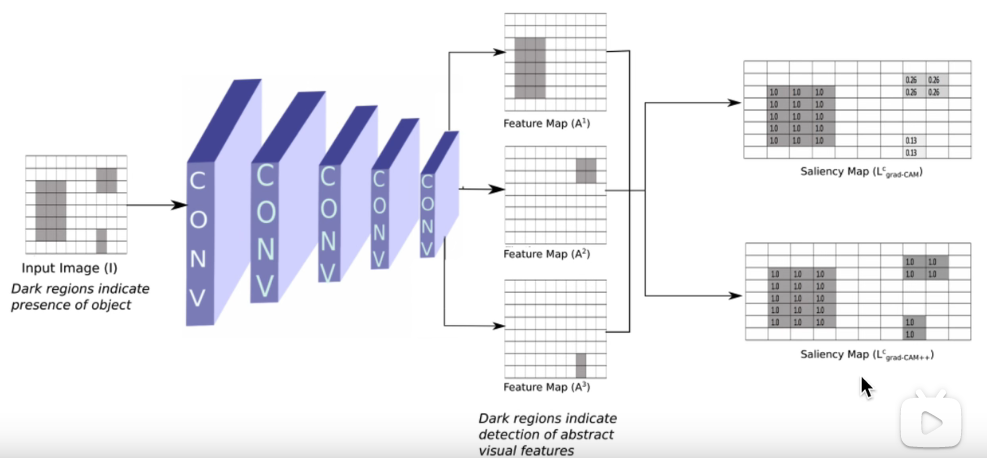
后续算法—ScoreCAM
解决了三个问题
- 梯度饱和、梯度消失、梯度噪声
- 权重大的channel,不一定对类别预测分数贡献大
- 只考虑从后往前的反向传播梯度,没考虑前向预测的影响
后续算法—LaayerCAM
解决了
- 深层生成的粗粒度热力图和浅层生成的细粒度热力图 都不够精准
赞赏
 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏